機器學習筆記(三) - 資訊熵
資訊熵(Shannon entropy)
在資訊理論中,熵是指接收的每條消息中包含的資訊的平均量,為不確定性的量度,越隨機的信源熵越大,又被稱為資訊熵、信源熵、平均資訊本體。依據 Boltzmann's H-theorem,Shannon 把隨機變量 \(X\) 的熵值 \(H\)(希臘字母Eta)定義如下,其值域為 \(\{x_1, \cdots, x_n\}\):
\[\mathrm {H}(X)=\mathrm {E}[\ \mathrm {I} (X)\ ]=\mathrm {E} [-\ln(\mathrm {P} (X))]\]其中,\(\mathrm {P}\) 為 \(X\) 的機率質量函數(probability mass function),\(\mathrm {E}\) 為期望函數,而 \(\mathrm{I}(X)\) 是 \(X\) 的資訊量(又稱為資訊本體)。 \(\mathrm{I}(X)\) 本身是個隨機變數。當取自有限的樣本時,熵的公式可以表示為:
\[\mathrm {H} (X)=\sum _{i}{\mathrm {P} (x_{i})\,\mathrm {I} (x_{i})}=-\sum _{i}{\mathrm {P} (x_{i})\,\log_b\mathrm {P} (x_{i})}\]在這裡 \(b\) 是對數所使用的底,當 \(b = 2\),熵的單位是 bit;當 \(b = e\),熵的單位是 nat;而當 \(b = 10\),熵的單位是 Hart。 若存在 \(p_i = 0\) 時,對應的被加數值將會是 \(0\),這與極限一致。
\begin{align}\lim _{p\to 0^+}p\log p &=\lim _{q\to \infty}\frac{1}{q}\log{\frac{1}{q}}\\ &=\lim _{q\to \infty}\frac{-\log q}{q}\\&=\lim _{q\to \infty}\frac{-1}{q}\qquad\qquad\qquad\qquad\text{(by L'Hospital's rule)}\\&=0 \end{align}最大熵(Maximum entropy)
熵是隨機變量不確定性的度量,不確定性越大,熵值越大;若隨機變量退化成定值,熵為0。如果沒有外界干擾,隨機變量總是趨向於無序,在經過足夠時間的穩定演化,它應該能夠達到的最大程度的熵。
為了準確的估計隨機變量的狀態,我們一般習慣性最大化熵,認為在所有可能的概率模型(分佈)的集合中,熵最大的模型是最好的模型。換言之,在已知部分知識的前提下,關於未知分佈最合理的推斷就是符合已知知識最不確定或最隨機的推斷,其原則是承認已知事物(知識),且對未知事物不做任何假設,沒有任何偏見。
例如,投擲一個骰子,如果問"每個面朝上的概率分別是多少",你會說是等概率,即各點出現的概率均為1/6。因為對這個"一無所知"的骰子,什麼都不確定,而假定它每一個朝上概率均等則是最合理的做法。從投資的角度來看,這是風險最小的做法,而從信息論的角度講,就是保留了最大的不確定性,也就是說讓熵達到最大。
我們要最大化的函數為 \(\mathrm{H}(X) = -\int_a^b \mathrm{P}(x)\log\mathrm{P}(x)dx\),固定限制條件為 \(\int_a^b \mathrm{P}(x)dx = 1\),其中隨機變數 \(X\) 的定義域為 \(x \in [a, b]\),下方根據給定不同限制條件來求出最大熵時隨機變數 \(X\) 的分布:
無其他已知條件
根據拉格朗日乘數法,其 Lagrange function 為:
\begin{align}\mathcal{L}(\mathrm{P}(x), \lambda)&=-\int_a^b \mathrm{P}(x)\log\mathrm{P}(x)dx + \lambda(\int_a^b \mathrm{P}(x)dx -1) \\ &=\int_a^b \lambda\mathrm{P}(x) - \mathrm{P}(x)\log\mathrm{P}(x)dx - \lambda\end{align}藉由 歐拉-拉格朗日方程式(Euler-Lagrange equation)可以得到(另外要注意的是,歐拉-拉格朗日方程式求得的僅為局部平穩值,並不一定是最大最小值):
\[\frac{\partial(\lambda\mathrm{P}(x) - \mathrm{P}(x)\log\mathrm{P}(x))}{\partial \mathrm{P}(x)} = 0\] \[\Rightarrow \lambda - \log\mathrm{P}(x)-1 = 0 \\ \Rightarrow\log\mathrm{P}(x) = \lambda -1\\ \mathrm{P}(x) = e^{\lambda -1}\]帶回限制條件:
\[\int_a^b \mathrm{P}(x)dx = 1 \\ \Rightarrow \int_a^b e^{\lambda -1} dx = 1\\ \Rightarrow (b-a) e^{\lambda -1} = 1\\ \Rightarrow \mathrm{P}(x) = e^{\lambda -1} = \frac{1}{b-a}\]已知平均值
令 \(\int_a^b x\mathrm{P}(x)dx = \mu\),根據拉格朗日乘數法,其 Lagrange function 為:
\begin{align}\mathcal{L}(\mathrm{P}(x), \lambda)&=-\int_a^b \mathrm{P}(x)\log\mathrm{P}(x)dx + \lambda_1(\int_a^b \mathrm{P}(x)dx -1)+\lambda_2(\int_a^b x\mathrm{P}(x)dx -\mu) \\ &=\int_a^b \lambda_1\mathrm{P}(x)+\lambda_2x\mathrm{P}(x)-\mathrm{P}(x)\log\mathrm{P}(x)dx -\lambda_1 -\lambda_2\mu\end{align}藉由 歐拉-拉格朗日方程式(Euler-Lagrange equation)可以得到:
\[\lambda_1+\lambda_2x- \log\mathrm{P}(x)-1=0\\ \Rightarrow \mathrm{P}(x) = e^{\lambda_1+\lambda_2x-1}\]帶回限制條件 \(\int_a^b \mathrm{P}(x)dx = 1\):
\[\int_a^b \mathrm{P}(x)dx = 1 \\ \Rightarrow \int_a^b e^{\lambda_1+\lambda_2x-1} dx = 1\\ \Rightarrow e^{\lambda_1-1}\int_a^b e^{\lambda_2x} dx = 1\\ \Rightarrow\frac{1}{\lambda_2}e^{\lambda_2x}\mid_a^b = e^{1-\lambda_1}\\ \Rightarrow\frac{1}{\lambda_2}(e^{\lambda_2b} - e^{\lambda_2a})=e^{1-\lambda_1}\]帶到第二個已知條件 \(\int_a^b x\mathrm{P}(x)dx = \mu\):
\[\int_a^b x\mathrm{P}(x)dx = \mu\\ \Rightarrow\int_a^b xe^{\lambda_1+\lambda_2x-1}dx = \mu\\ \Rightarrow e^{\lambda_1-1}\int_a^b xe^{\lambda_2x} dx = \mu\\ \Rightarrow \frac{1}{\lambda_2}x e^{\lambda_2x}\mid_a^b - \int_a^b\frac{1}{\lambda_2}e^{\lambda_2x}dx = \mu e^{1-\lambda_1}\qquad\qquad\qquad\text{(integration by parts)}\\ \Rightarrow \frac{1}{\lambda_2}\left[be^{\lambda_2b}-ae^{\lambda_2a} - (\frac{1}{\lambda_2}e^{\lambda_2x})\Big|_a^b\right] = \mu e^{1-\lambda_1}\\ \Rightarrow \frac{1}{\lambda_2}\left[be^{\lambda_2b}-ae^{\lambda_2a} - \frac{1}{\lambda_2}e^{\lambda_2b} + \frac{1}{\lambda_2}e^{\lambda_2a}\right] = \frac{1}{\lambda_2}\mu(e^{\lambda_2b} - e^{\lambda_2a})\\ \Rightarrow (b - \mu - \frac{1}{\lambda_2})e^{\lambda_2b} = (a - \mu - \frac{1}{\lambda_2})e^{\lambda_2a} \]上式為超越方程,求不出解析解,並且從等式中可以看出,若 \(a\to-\infty,\ b\to\infty\)必定無解,不妨考慮 \(a = 0,\ b\to\infty\):
根據限制條件\(\int_a^b \mathrm{P}(x)dx = 0\):
\begin{align}\frac{1}{\lambda_2}e^{\lambda_2x}\mid_a^b = e^{1-\lambda_1} &\Rightarrow\lim_{b\to \infty}\frac{1}{\lambda_2}(e^{\lambda_2b} - 1)=e^{1-\lambda_1} \\ &\Rightarrow \frac{-1}{\lambda_2}=e^{1-\lambda_1} \qquad\qquad\qquad(\because\lambda_2\le0)\\ &\Rightarrow \lambda_2 = - e^{\lambda_1-1}\end{align}根據第二個已知條件\(\int_a^b x\mathrm{P}(x)dx = \mu\):
\begin{align}\frac{1}{\lambda_2}\left[be^{\lambda_2b}-ae^{\lambda_2a} - (\frac{1}{\lambda_2}e^{\lambda_2x})\Big|_a^b\right] = \mu e^{1-\lambda_1} &\Rightarrow \lim_{b\to \infty}\frac{1}{\lambda_2}\left[be^{\lambda_2b} - \frac{1}{\lambda_2}e^{\lambda_2b} + \frac{1}{\lambda_2}\right] =- \frac{\mu}{\lambda_2}\\ &\Rightarrow \lim_{b\to \infty}be^{\lambda_2b} - \frac{1}{\lambda_2}e^{\lambda_2b} + \frac{1}{\lambda_2} = -\mu \\ &\Rightarrow \frac{1}{\lambda_2} = -\mu \\ &\Rightarrow \lambda_2 = -\frac{1}{\mu}\end{align}代回 \(\mathrm{P}(x)\):
\begin{align}\mathrm{P}(x) &= e^{\lambda_1+\lambda_2x-1} \\ &=e^{\lambda_1-1}\times e^{\lambda_2x} \\ &=-\lambda_2 e^{\lambda_2x} \\ &=\frac{1}{\mu} e^{-x/\mu}\end{align}聯合熵(joint entropy)、條件熵(conditional entropy)和相對熵(relative entropy)
聯合熵(joint entropy)
給定隨機變量 \(X\) 與 \(Y\),定義域分別爲 \(\mathcal X\) 與 \(\mathcal Y\),其聯合熵定義為:
\[\mathrm{H}(X,Y)=-\sum _{x \in \mathcal X}\sum _{y \in \mathcal Y}\mathrm{P}(x,y)\log _{2}[P(x,y)]\]其中 \(\mathrm{P}(x,y)\) 為聯合機率(joint probability)。
條件熵(conditional entropy)
條件熵描述了在已知第二個隨機變量 \(X\) 的值的前提下,隨機變量 \(Y\) 的信息熵還有多少。如果 \(\mathrm{H} (Y|X=x)\) 爲變數 \(Y\) 在變數 \(X\) 取特定值 \(x\) 條件下的熵,那麼 \(\mathrm{H} (Y|X)\) 就是 \(\mathrm{H} (Y|X=x)\) 在 \(X\) 取遍所有可能的 \(x\) 後取平均的結果。
給定隨機變量 \(X\) 與 \(Y\),定義域分別爲 \(\mathcal X\) 與 \(\mathcal Y\),在給定 \(X\) 條件下 \(Y\) 的條件熵定義爲:
\begin{align} H(Y|X) &= \sum_{x \in \mathcal X} {p(x)H(Y|X = x)} \\ &= - \sum_{x \in \mathcal X} {p(x)} \sum_{y \in \mathcal Y} {p(y|x)\log p(y|x)} \\ &= - \sum_{x \in \mathcal X} {\sum_{y \in \mathcal Y} {p(x,y)\log p(y|x)} } \end{align}鏈式法則:\(H(X,Y) = H(X) + H(Y|X)\)
其證明如下
\begin{align} H(X,Y) &= - \sum_{x \in \mathcal X} {\sum_{y \in\mathcal Y} {p(x,y)\log p(x,y)} } \\ &= - \sum_{x \in\mathcal X} {\sum_{y \in\mathcal Y} {p(x,y)\log p(x)p(y|x)} } \\ &= - \sum_{x \in\mathcal X} {\sum_{y \in\mathcal Y} {p(x,y)\log p(x)} } - \sum_{x \in\mathcal X} {\sum_{y \in\mathcal Y} {p(x,y)\log p(y|x)} } \\ &= - \sum_{x \in\mathcal X} {p(x)\log p(x)} - \sum_{x \in\mathcal X} {\sum_{y \in\mathcal Y} {p(x,y)\log p(y|x)} } \\ &= H(X) + H(Y|X) \end{align}交叉熵(cross entropy)
現有關於樣本集的 2 個概率分佈 \(p\) 和 \(q\),其中 \(p\) 為真實分佈, \(q\) 非真實分佈。按照真實分佈 \(p\) 來衡量識別一個樣本的所需要的編碼長度的期望(即平均編碼長度)為:
\[\mathrm{H}(p)=\sum_i p(i)\log \frac{1}{p(i)}\]如果使用錯誤分佈 \(q\) 來表示來自真實分佈 \(p\) 的平均編碼長度,則應該是:
\[\mathrm{H}(p,q)=\sum_i p(i)\log \frac{1}{q(i)}\]因為用 \(q\) 來編碼的樣本來自分佈 \(p\),所以期望 \(H(p,q)\) 中概率是 \(p(i)\)。 \(H(p,q)\) 我們稱之為"交叉熵"。
相對熵(relative entropy, KL divergence)
我們將由 \(q\) 得到的平均編碼長度比由 \(p\)得到的平均編碼長度多出的 bit 數稱為“相對熵”:
\[D(p||q)=H(p,q)-H(p)=\sum_i p(i) \log \frac{p(i)}{q(i)}\]其又被稱為 KL散度(Kullback–Leibler divergence,KLD)。它表示 2 個函數或概率分佈的差異性:差異越大則相對熵越大,差異越小則相對熵越小,特別地,若2者相同則熵為0。注意,KL散度為非對稱性量度,一般來說 \(D\left( {p||q} \right) \ne D\left( {q||p} \right)\),而且也不滿足三角不等式,因此它實際上並不是兩個分佈之間的真正距離。然而,將相對熵視作分佈之間的"距離"往往會很有用。。
互信息(Mutual Information)
互信息是一個隨機變量包含另一個隨機變量信息量的度量。互信息也是在給定另一個隨機變量知識的條件下,原隨機變量不確定度的縮減量。
定義:考慮兩個隨機變量 \(X\) 和 \(Y\),它們的聯合概率密度函數為 \(p(x,y)\),其邊緣概率密度函數分別為 \(p(x),\ p(y)\)。互信息 \(I(X;Y)\) 為聯合分佈 \(p(x,y)\) 和乘積分佈 \(p(x)p(y)\) 之間的相對熵,即:
\begin{align} I(X;Y) &= \sum_{x \in \mathcal{X}} \sum_{y \in \mathcal{Y}} p(x,y)\log \frac{p(x,y)}{p(x)p(y)} \\ &= D(p(x,y)\ ||\ p(x)p(y))\\ &= E_{p(x,y)}\left[\log \frac{p(X,Y)}{p(X)p(Y)}\right] \end{align}熵與互信息的關係
可將互信息 \(I(X;Y)\) 重新寫為:
\begin{align} I(X;Y) &= \sum_{x \in \mathcal{X},\ y \in \mathcal{Y}} {p(x,y)\log \frac{{p(x,y)}}{{p(x)p(y)}}} \\ &= \sum_{x \in \mathcal{X},\ y \in \mathcal{Y}} {p(x,y)\log \frac{{p(x|y)}}{{p(x)}}} \\ &= - \sum_{x \in \mathcal{X}} {\sum_{y \in \mathcal{Y}} {p(x,y)\log p(x)} } + \sum_{x \in \mathcal{X}} {\sum_{y \in \mathcal{Y}} {p(x,y)\log p(x|y)} } \\ & = - \sum_{x \in \mathcal{X}} {p(x)\log p(x)} - ( - \sum_{x \in \mathcal{X}} {\sum_{y \in \mathcal{Y}} {p(x,y)\log p(x|y)} } )\\ &= H(X) - H(X|Y) \end{align}由此可見,互信息 \(I(X;Y)\) 是在給定另一個隨機變量 \(Y\) 知識的條件下,\(X\) 不確定度的縮減量。由於互信息的對稱性,可得:
\[I(X;Y) = I(Y;X) = H(Y) - H(Y|X)\]由於之前已經得到表達式 \(H(X,Y) = H(X) + H(Y|X)\),代入上式可得:
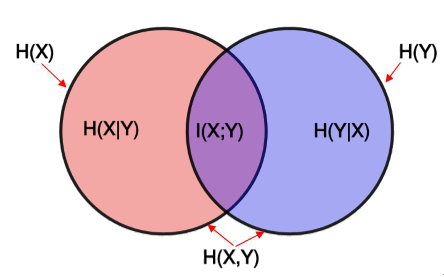
\[I(X;Y) = H(X) + H(Y) - H(X,Y)\]把之前的一些重要表達式都放在一塊:
\[ I(X;Y) = H(X) - H(X|Y)\\ I(X;Y) = H(Y) - H(Y|X)\\ I(X;Y) = H(X) + H(Y) - H(X,Y)\\ I(X;Y) = I(Y;X) \]實際上,韋恩圖可以很好地表示以上各變量之間的關係,對著上面的公式,應該可以很好理解下面的圖表達的含義。

留言
張貼留言